publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
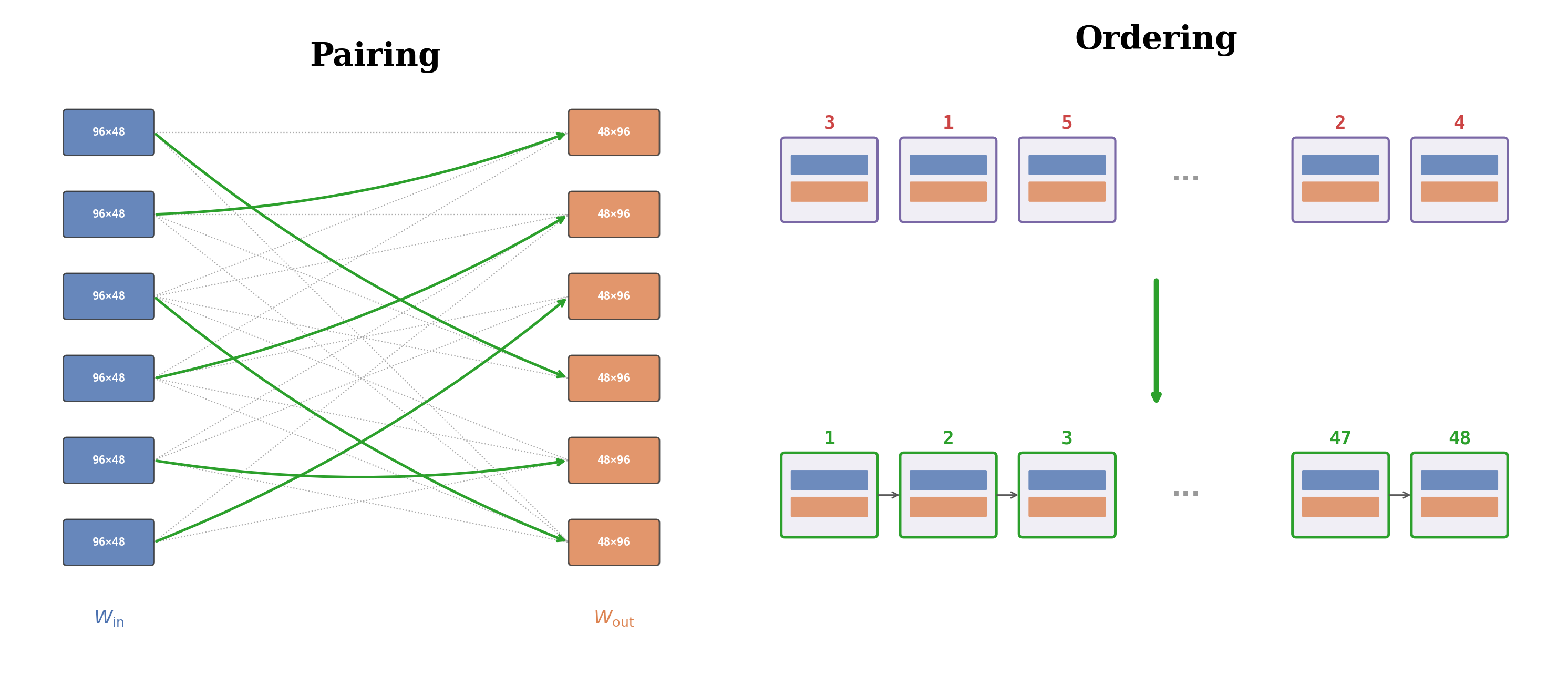 I Dropped a Neural NetHyunwoo ParkFeb 2026
I Dropped a Neural NetHyunwoo ParkFeb 2026A recent Dwarkesh Patel podcast with John Collison and Elon Musk featured an interesting puzzle from Jane Street: they trained a neural net, shuffled all 96 layers, and asked to put them back in order. Given unlabelled layers of a Residual Network and its training dataset, we recover the exact ordering of the layers. The problem decomposes into pairing each block’s input and output projections (48! possibilities) and ordering the reassembled blocks (48! possibilities), for a combined search space of (48!)^2 approximately 10^122, which is more than the atoms in the observable universe. We show that stability conditions during training like dynamic isometry leave the product W_out W_in for correctly paired layers with a negative diagonal structure, allowing us to use diagonal dominance ratio as a signal for pairing. For ordering, we seed-initialize with a rough proxy such as delta-norm then hill-climb to zero mean squared error.

2025
-
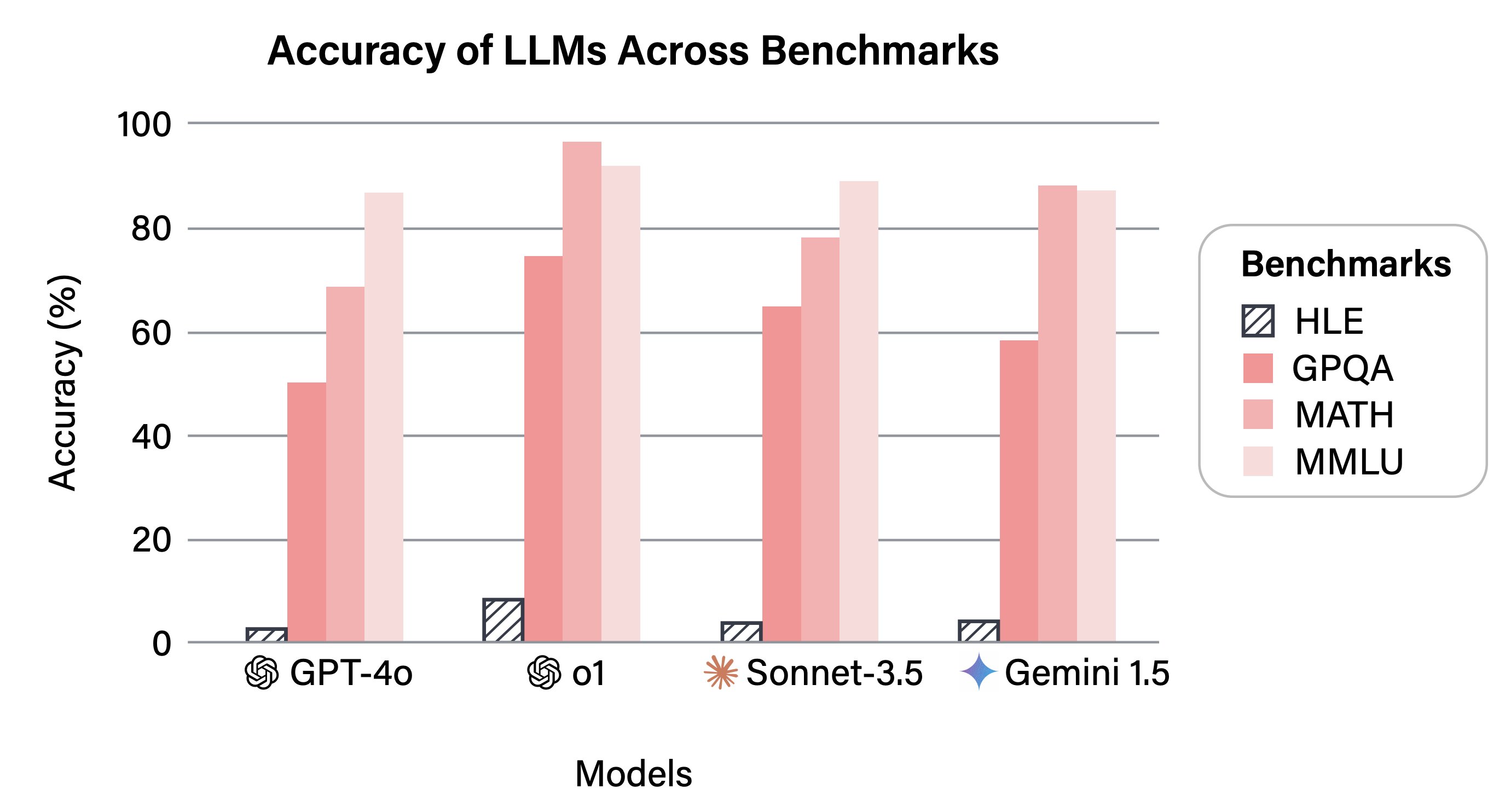 Humanity’s Last ExamLong Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, and 657 more authorsNature, Jan 2025
Humanity’s Last ExamLong Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, and 657 more authorsNature, Jan 2025Benchmarks are important tools for tracking the rapid advancements in large lan- guage model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce HUMANITY’S LAST EXAM (HLE), a multi-modal bench- mark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and con- sists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demon- strate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.

2024
-
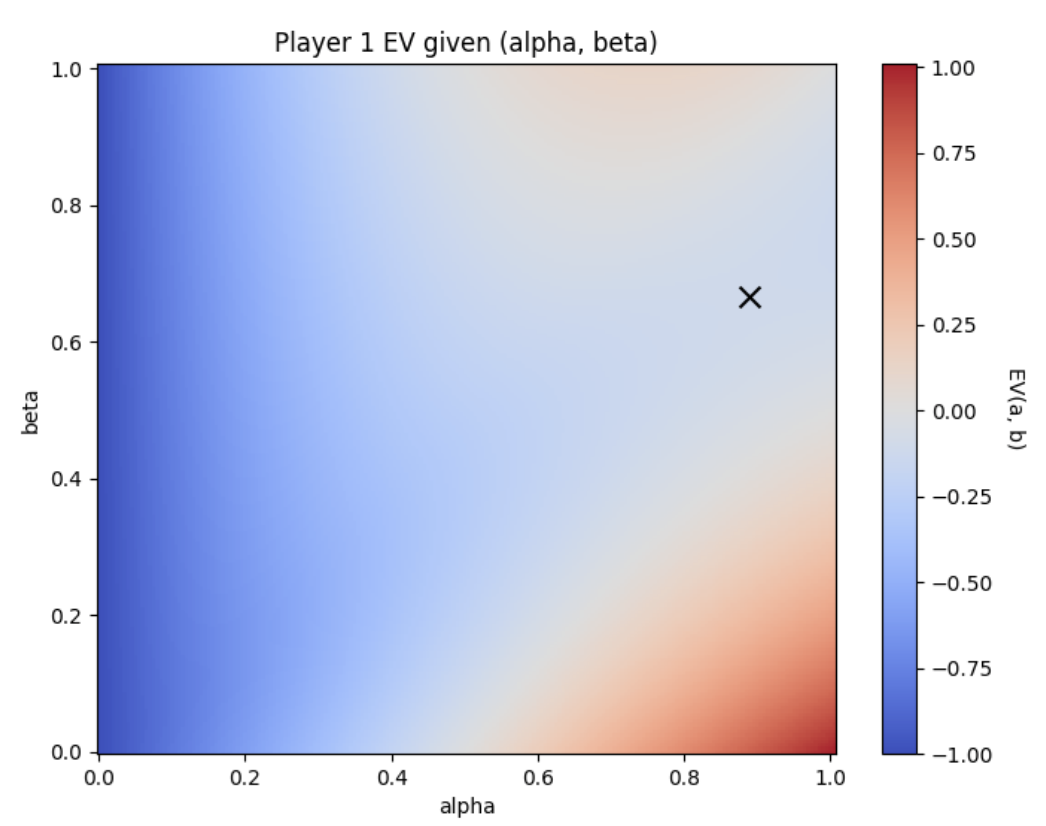 Multiplayer Guts Poker with Staggered PayoutsHyunwoo Park*, and Shiva Oswal*Dec 2024
Multiplayer Guts Poker with Staggered PayoutsHyunwoo Park*, and Shiva Oswal*Dec 2024Multiplayer poker tournaments with staggered payouts present complex strategic challenges distinct from two-player zero-sum games. Traditional models like the Independent Chip Model offer heuristics for chip-to-monetary value conversion but fall short in capturing the nuanced incentives in multi-player settings. We introduce a simplified variant of Guts poker to analytically and computationally explore equilibrium strategies in tournaments with more than two players. For the two-player case, we derive a unique Nash equilibrium with closed-form threshold strategies, highlighting positional advantages. Extending to multiplayer scenarios, we develop a Monte Carlo-based fictitious play algorithm to approximate equilibria, uncovering phenomena such as middle stack pressure. Our findings advance the understanding of tournament poker dynamics.
-
 Visual Story GenerationNevan Giuliani, Maxwell Jones, Alex Lyons, and Hyunwoo ParkMay 2024
Visual Story GenerationNevan Giuliani, Maxwell Jones, Alex Lyons, and Hyunwoo ParkMay 2024In this project we attempt to expand the task of visual storytelling by producing both story captions and images for the remainder of a story just given one initial frame (image and caption). Much previous work on this task focus on generating story captions from images or story images from captions. However, we present a pipeline for doing both simultaneously while ensuring that we have coherence between the story captions, coherence between the images, and alignment between the text and images. The key insight we make in our approach is that story captions are poor inputs to diffusion models so we generate both story captions as well as descriptive captions, the latter of which is used as input in image generation.


2023
-
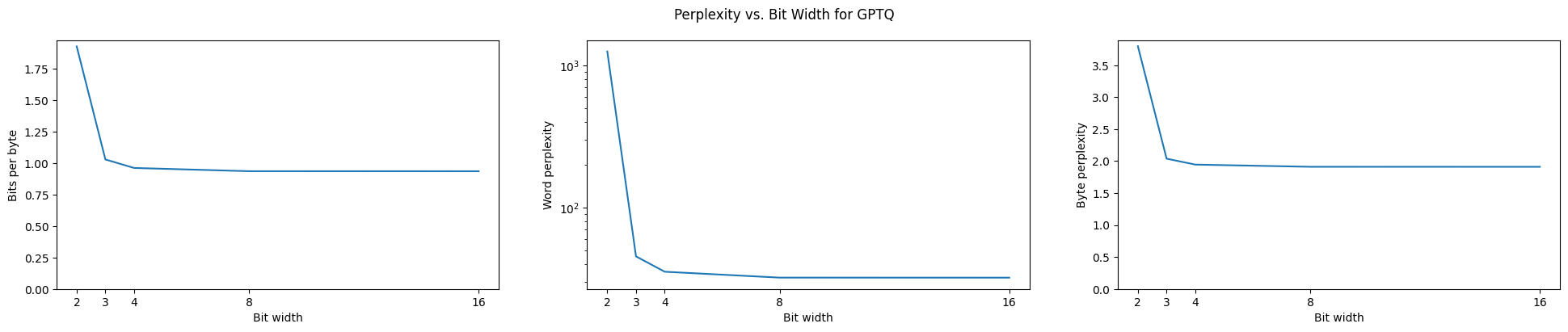 A Brief Survey of Model Compression in Language ModelsBrandon Dong, Russell Emerine, Aresh Pourkavoos, and Hyunwoo ParkDec 2023
A Brief Survey of Model Compression in Language ModelsBrandon Dong, Russell Emerine, Aresh Pourkavoos, and Hyunwoo ParkDec 2023Large Language Models are the state of the art for many natural language processing tasks, and their versatility makes them appealing in a variety of applications. However, such models have serious storage and computational demands, and the field of model compression works to lower those requirements. While model compression, especially for deep neural networks, has existed as a field before the advent of LLMs, the size and scope of these models present unique challenges to the pre-existing methods. Promising solutions include new techniques in knowledge distillation, quantization, pruning, and low-rank factorization that can generate significantly smaller models while remaining performant. In this report we provide a detailed review and some empirical verification of these methods, compare their relative advantages and disadvantages, and discuss the state of the field today. For brevity, we will not discuss inference acceleration, efficient prompting, or hardware methods; we focus instead on techniques that concern themselves with memory footprint.
